Learning to Segment Liquids in Real-world Images
Jonas Li, Michelle Li, Luke Liu, Xiaohui Yuan, Heng Fan

Abstract
Liquids like water, wine and medicine are everywhere. However, limited attention has been given to the task of segmenting liquids, hindering the ability of robots to safely avoid and interact with them. The segmentation of liquids is difficult because liquids come in diverse appearances and shapes; moreover, they can be both transparent or reflective, taking on arbitrary objects and scenes from their background and surroundings. To take on this challenge, we construct a liquid dataset, LQDS, consisting of 5000 real-world images annotated into 14 distinct classes, and design a novel liquid detection model, LQDM, which leverages cross-attention between a dedicated boundary branch and the main segmentation branch to enhance mask predictions. Extensive experiments demonstrate the effectiveness of LQDM on the testing set of LQDS, outperforming state-of-the-art methods to establish a strong baseline for the semantic segmentation of liquids. We believe that LQDS and LQDM will facilitate future research in liquid segmentation and enable practical applications in robotics.
Benchmark

LQDS contains 5K images of liquids, each with corresponding liquid masks. The liquid objects in the images are categorized into 14 classes: water, wine, juice, cocktails, soda, coffee, tea, boba, chemical, medical, milk, spirits, honey, and miscellaneous.
Method
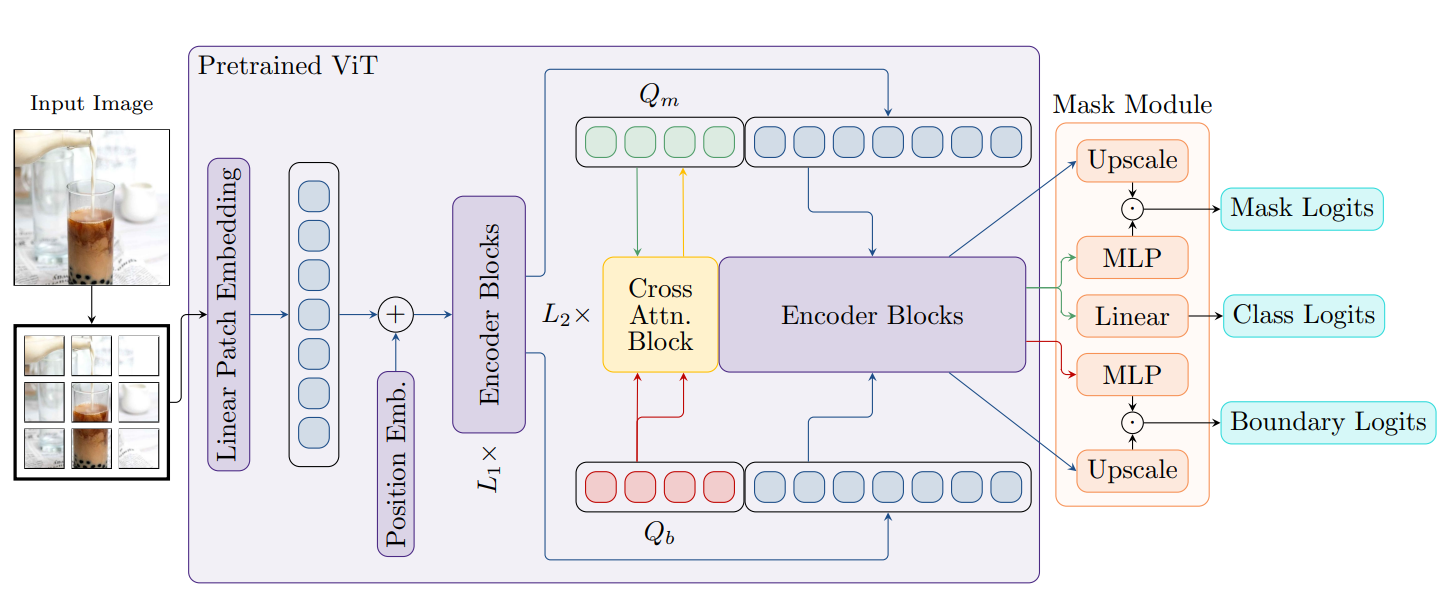
The proposed LQDM is a dual-branch architecture which injects boundary features into segmentation mask predictions through cross-attention, setting the benchmark for the liquid segmentation task with a 59.28% mean IoU and a 71.61% mean pixel-accuracy.